What is Hive?

Apache Hive is a distributed, fault-tolerant data warehouse system, built on top of Hadoop, designed to simplify and streamline the processing of large datasets.
Through Hive, a user can manage and analyze massive volumes of data by organizing it into tables, resembling a traditional relational database.
Hive uses the HiveQL (HQL) language, which is very similar to SQL. These SQL-like queries get translated into MapReduce tasks, leveraging the power of Hadoop’s MapReduce functionalities while bypassing the need to know how to program MapReduce jobs.
Hive abstracts the complexity of Java-based utilization of Hadoop’s file storage system. It is best used for traditional data warehousing tasks.
In this blog post, we will look at installing Hive on a Hadoop cluster utilizing Ansible!
What is Ansible?
Ansible is an open-source IT automation tool that allows for automated management of remote systems.
![]()
A basic Ansible environment has the following three components:
Control Node: This is a system on which Ansible is installed, and the system from which Ansible commands such as
ansible-inventoryare issued. This is also where Ansible playbooks and configuration files are stored.Managed node: This is a remote system that Ansible intends to manage and configure.
Inventory: This is a list of managed nodes that are organized locally on the control node. This lists the IP addresses or the hostnames of the remote systems being managed along with any connection information needed.
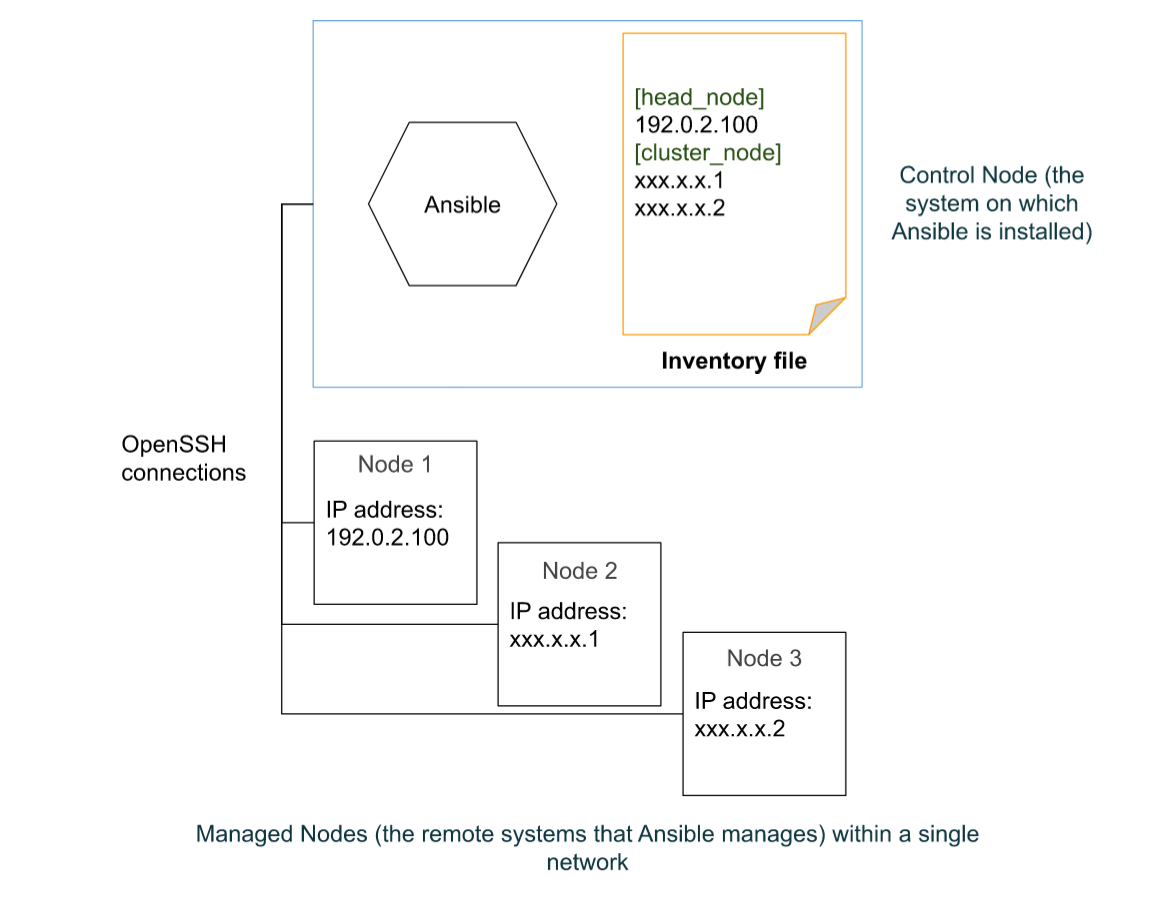
I have a blog post detailing the basics of Ansible and it’s relevance in a computing cluster here!.
Prerequisites for this blog post
An installation of Ansible (In a previous post, I set up Ansible in a Docker container, minimizing the overhead on the actual cluster nodes).
Password-less SSH connections set up between each node and the node (or container) you are running Ansible from.
The inventory file, defined at
/etc/Ansible/hosts.An installation of Hadoop, with HDFS, YARN, MapReduce and Spark configured and running. This post covers the basic overview of the installation and configuration of Hadoop and Spark.
I used Ansible from a Docker container to configure a 4 node cluster. The cluster inventory file is in the INI format as follows:
[cluster]
XXX.XX.XXX.X
YY.Y.Y.2
YY.Y.Y.3
YY.Y.Y.4
[head_node]
XXX.XX.XXX.X
[cluster_nodes]
YY.Y.Y.2
YY.Y.Y.3
YY.Y.Y.4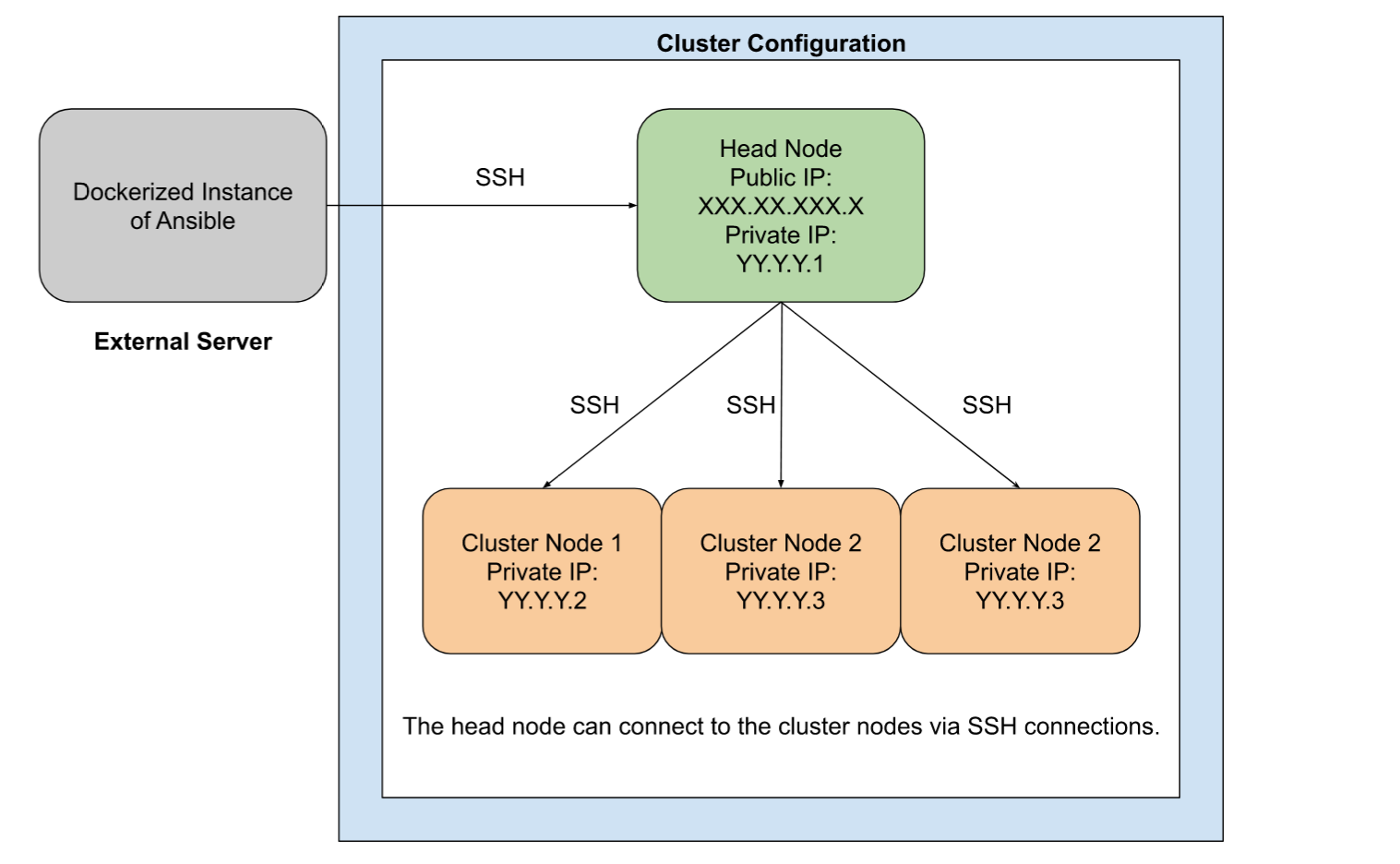
What are Playbooks?
Ansible playbooks provide a simple and reusable method to define the configuration and management of multi-machine systems, and is well equipped to handling tasks that can range from simple ones like installing software packages to complex ones like configuring multiple servers with specific roles.
Playbook Syntax
YAML (YAML Ain’t Markup Language) is a human-readable data serialization format that plays a pivotal role in Ansible playbooks.
YAML files use key-value pairs, lists, and nested structures to represent data. It eschews complex symbols, relying instead on whitespace and line breaks to delineate data structures, making it easy to grasp and write, even for those without extensive programming experience.
Playbooks are automation blueprints. Playbooks contain plays, which are a list of tasks that map to each managed node in the predefined inventory.
Tasks are a list of one or more modules that define the operations that Ansible can perform.
A Module is a unit of code that Ansible can run on managed nodes.
Each play defines two things:
The managed nodes to target.
At least one task to execute.
An Example Playbook!
Let’s jump right in! The following is a playbook that installs Hive on a cluster with a head node and 3 cluster nodes.
The head node runs Rhel 8 and the 3 cluster nodes run Ubuntu.
- name: Installing Apache Hive and its prerequisties on the RHEL 8 head node.
hosts: head_node
become: true
become_user: temp
become_method: sudo
tasks:
- name: Installing Maven on the RHEL 8 head node
ansible.builtin.get_url:
url: https://dlcdn.apache.org/maven/maven-3/3.9.4/binaries/apache-maven-3.9.4-bin.tar.gz
dest: /tmp/apache-maven-3.9.4-bin.tar.gz
checksum: "sha512:https://downloads.apache.org/maven/maven-3/3.9.4/binaries/apache-maven-3.9.4-bin.tar.gz.sha512"
- name: Decompressing the Maven tarball on the Rhel 8 head node
ansible.builtin.unarchive:
src: /tmp/apache-maven-3.9.4-bin.tar.gz
dest: /opt/
remote_src: yes
- name: Adding the Maven `bin` directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export PATH=$PATH:/opt/apache-maven-3.9.4/bin
- name: Downloading Apache Hive for the RHEL 8 head node
ansible.builtin.get_url:
url: https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
dest: /tmp/apache-hive-3.1.3-bin.tar.gz
checksum: "sha256:https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz.sha256"
timeout: 60
- name: Decompressing the Apache Hive tarball for the RHEL 8 head node
ansible.builtin.unarchive:
src: /tmp/apache-hive-3.1.3-bin.tar.gz
dest: /opt/
remote_src: yes
- name: Adding the installation directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export HIVE_HOME=/opt/apache-hive-3.1.3-bin
- name: Adding the installation directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export PATH=$PATH:$HIVE_HOME/bin
- name: Editing the log4j.properties file
ansible.builtin.blockinfile:
path: /opt/hadoop-3.3.6/etc/hadoop/log4j.properties
insertafter: EOF
block: |
# Define an appender for the MRAppMaster logger
log4j.logger.org.apache.hadoop.mapreduce.v2.app.MRAppMaster=INFO, mrappmaster
# Appender for MRAppMaster logger
log4j.appender.mrappmaster=org.apache.log4j.ConsoleAppender
log4j.appender.mrappmaster.layout=org.apache.log4j.PatternLayout
log4j.appender.mrappmaster.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
- name: Reloading the shell
ansible.builtin.shell: source ~/.bashrc
- name: Configuring Hive on the RHEL 8 head node.
hosts: head_node
remote_user: temp
become_user: temp
become: true
become_method: sudo
tasks:
- name: Configuring the Hive Warehouse using hadoop
ansible.builtin.shell: |
source ~/.bashrc
export HADOOP_HOME=/opt/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HIVE_HOME=/opt/apache-hive-3.1.3-bin
export PATH=$PATH:$HIVE_HOME/bin
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user
hadoop fs -mkdir /user/hive
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
schematool -dbType derby -initSchema
args:
executable: /bin/bash
- name: Creating a hive-site.xml file
copy:
dest: /opt/apache-hive-3.1.3-bin/conf/hive-site.xml
content: |
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/metastore</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hivepassword</value>
</property>
- name: Configuring Spark to use the Hive Metastore
ansible.builtin.lineinfile:
path: /opt/spark-3.3.2-bin-hadoop3/conf/spark-defaults.conf
insertafter: EOF
line: spark.sql.warehouse.dir=hdfs://localhost:9000/user/hive/warehouse
- name: Installing Apache Hive and its prerequisties on the Ubuntu cluster nodes.
hosts: cluster_nodes
remote_user: temp
become: true
become_method: sudo
tasks:
- name: Installing Maven on the RHEL 8 head node
ansible.builtin.get_url:
url: https://dlcdn.apache.org/maven/maven-3/3.9.4/binaries/apache-maven-3.9.4-bin.tar.gz
dest: /tmp/apache-maven-3.9.4-bin.tar.gz
checksum: "sha512:https://downloads.apache.org/maven/maven-3/3.9.4/binaries/apache-maven-3.9.4-bin.tar.gz.sha512"
- name: Decompressing the Maven tarball on the Rhel 8 head node
ansible.builtin.unarchive:
src: /tmp/apache-maven-3.9.4-bin.tar.gz
dest: /opt/
remote_src: yes
- name: Adding the Maven `bin` directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export PATH=$PATH:/opt/apache-maven-3.9.4/bin
- name: Downloading Apache Hive for the RHEL 8 head node
ansible.builtin.get_url:
url: https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
dest: /tmp/apache-hive-3.1.3-bin.tar.gz
checksum: "sha256:https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz.sha256"
timeout: 60
- name: Decompressing the Apache Hive tarball for the RHEL 8 head node
ansible.builtin.unarchive:
src: /tmp/apache-hive-3.1.3-bin.tar.gz
dest: /opt/
remote_src: yes
- name: Adding the installation directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export HIVE_HOME=/opt/apache-hive-3.1.3-bin
- name: Adding the installation directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export PATH=$PATH:$HIVE_HOME/bin
- name: Editing the log4j.properties file
ansible.builtin.blockinfile:
path: /opt/hadoop-3.3.6/etc/hadoop/log4j.properties
insertafter: EOF
block: |
# Define an appender for the MRAppMaster logger
log4j.logger.org.apache.hadoop.mapreduce.v2.app.MRAppMaster=INFO, mrappmaster
# Appender for MRAppMaster logger
log4j.appender.mrappmaster=org.apache.log4j.ConsoleAppender
log4j.appender.mrappmaster.layout=org.apache.log4j.PatternLayout
log4j.appender.mrappmaster.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
- name: Reloading the environment variables
ansible.builtin.shell: |
. /home/temp/.bashrc
args:
executable: /bin/bash
- name: Configuring the Hive Warehouse using hadoop
ansible.builtin.shell: |
. /home/temp/.bashrc
export HADOOP_HOME=/opt/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HIVE_HOME=/opt/apache-hive-3.1.3-bin
export PATH=$PATH:$HIVE_HOME/bin
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user
hadoop fs -mkdir /user/hive
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
schematool -dbType derby -initSchema
args:
executable: /bin/bash
- name: Creating a hive-site.xml file
copy:
dest: /opt/apache-hive-3.1.3-bin/conf/hive-site.xml
content: |
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/metastore</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hivepassword</value>
</property>
- name: Configuring Spark to use the Hive Metastore
ansible.builtin.lineinfile:
path: /opt/spark-3.3.2-bin-hadoop3/conf/spark-defaults.conf
insertafter: EOF
line: spark.sql.warehouse.dir=hdfs://localhost:9000/user/hive/warehouseCode Breakdown
Let’s look at the code.
Part 1: Defining a play
- name: Installing Apache Hive and its prerequisties on the RHEL 8 head node.
hosts: head_node
become: true
become_user: temp
become_method: sudo
This section defines the play with the title “Installing Apache Hive and its prerequisties on the RHEL 8 head node”.
hosts defines the managed node to run this playbook on (in this case, the Rhel 8 head node, named head_node in the inventory file).
become tells Ansible that this play needs to be executed with elevated privileges.
become_user defines the user to run the commands defined by Ansible as. (in this case, temp is the user.)
become_method tells Ansible that the method to elevate the privilieges by is sudo.
Part 2: Downloading Hive (with it’s prerequisites)
tasks:
- name: Installing Maven on the RHEL 8 head node
ansible.builtin.get_url:
url: https://dlcdn.apache.org/maven/maven-3/3.9.4/binaries/apache-maven-3.9.4-bin.tar.gz
dest: /tmp/apache-maven-3.9.4-bin.tar.gz
checksum: "sha512:https://downloads.apache.org/maven/maven-3/3.9.4/binaries/apache-maven-3.9.4-bin.tar.gz.sha512"
- name: Decompressing the Maven tarball on the Rhel 8 head node
ansible.builtin.unarchive:
src: /tmp/apache-maven-3.9.4-bin.tar.gz
dest: /opt/
remote_src: yes
- name: Adding the Maven `bin` directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export PATH=$PATH:/opt/apache-maven-3.9.4/bin
- name: Downloading Apache Hive for the RHEL 8 head node
ansible.builtin.get_url:
url: https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
dest: /tmp/apache-hive-3.1.3-bin.tar.gz
checksum: "sha256:https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz.sha256"
timeout: 60
- name: Decompressing the Apache Hive tarball for the RHEL 8 head node
ansible.builtin.unarchive:
src: /tmp/apache-hive-3.1.3-bin.tar.gz
dest: /opt/
remote_src: yes
- name: Adding the installation directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export HIVE_HOME=/opt/apache-hive-3.1.3-bin
- name: Adding the installation directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export PATH=$PATH:$HIVE_HOME/bin
- name: Editing the log4j.properties file
ansible.builtin.blockinfile:
path: /opt/hadoop-3.3.6/etc/hadoop/log4j.properties
insertafter: EOF
block: |
# Define an appender for the MRAppMaster logger
log4j.logger.org.apache.hadoop.mapreduce.v2.app.MRAppMaster=INFO, mrappmaster
# Appender for MRAppMaster logger
log4j.appender.mrappmaster=org.apache.log4j.ConsoleAppender
log4j.appender.mrappmaster.layout=org.apache.log4j.PatternLayout
log4j.appender.mrappmaster.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
- name: Reloading the shell
ansible.builtin.shell: source ~/.bashrcThis code of chunk downloads Maven (a software project management and comprehension tool), and installs it, and then proceeds to download and install Hive, and then updates the .bashrc file to add the installed binaries.
Commands like ansible.builtin.blockinfile and ansible.builtin.get_url are modules that are built-in by Ansible to perform particular functions, and are part of each named task, which are themselves a part of each named play.
Part 3: Configuring Hive
- name: Configuring Hive on the RHEL 8 head node.
hosts: head_node
remote_user: temp
become_user: temp
become: true
become_method: sudo
tasks:
- name: Configuring the Hive Warehouse using hadoop
ansible.builtin.shell: |
source ~/.bashrc
export HADOOP_HOME=/opt/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HIVE_HOME=/opt/apache-hive-3.1.3-bin
export PATH=$PATH:$HIVE_HOME/bin
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user
hadoop fs -mkdir /user/hive
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
schematool -dbType derby -initSchema
args:
executable: /bin/bash
- name: Creating a hive-site.xml file
copy:
dest: /opt/apache-hive-3.1.3-bin/conf/hive-site.xml
content: |
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/metastore</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hivepassword</value>
</property>
- name: Configuring Spark to use the Hive Metastore
ansible.builtin.lineinfile:
path: /opt/spark-3.3.2-bin-hadoop3/conf/spark-defaults.conf
insertafter: EOF
line: spark.sql.warehouse.dir=hdfs://localhost:9000/user/hive/warehouseLet’s reiterate. The first few lines define the play, which is to configure Hive. What follows that are tasks, whice each have a name and run a module. This above chunk initiates the Hive warehouse and creates a hive-site.xml file to use so that Spark can detect and use the Hive Metastore. Modules are the commands like ansible.builtin.shell and ansible.builtin.lineinfile, and they execute specific functions.
Part 4: Downloading and configuring Hive for the cluster nodes
- name: Installing Apache Hive and its prerequisties on the Ubuntu cluster nodes.
hosts: cluster_nodes
remote_user: temp
become: true
become_method: sudo
tasks:
- name: Installing Maven on the RHEL 8 head node
ansible.builtin.get_url:
url: https://dlcdn.apache.org/maven/maven-3/3.9.4/binaries/apache-maven-3.9.4-bin.tar.gz
dest: /tmp/apache-maven-3.9.4-bin.tar.gz
checksum: "sha512:https://downloads.apache.org/maven/maven-3/3.9.4/binaries/apache-maven-3.9.4-bin.tar.gz.sha512"
- name: Decompressing the Maven tarball on the Rhel 8 head node
ansible.builtin.unarchive:
src: /tmp/apache-maven-3.9.4-bin.tar.gz
dest: /opt/
remote_src: yes
- name: Adding the Maven `bin` directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export PATH=$PATH:/opt/apache-maven-3.9.4/bin
- name: Downloading Apache Hive for the RHEL 8 head node
ansible.builtin.get_url:
url: https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
dest: /tmp/apache-hive-3.1.3-bin.tar.gz
checksum: "sha256:https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz.sha256"
timeout: 60
- name: Decompressing the Apache Hive tarball for the RHEL 8 head node
ansible.builtin.unarchive:
src: /tmp/apache-hive-3.1.3-bin.tar.gz
dest: /opt/
remote_src: yes
- name: Adding the installation directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export HIVE_HOME=/opt/apache-hive-3.1.3-bin
- name: Adding the installation directory to the PATH
ansible.builtin.lineinfile:
path: /home/temp/.bashrc
insertafter: EOF
line: export PATH=$PATH:$HIVE_HOME/bin
- name: Editing the log4j.properties file
ansible.builtin.blockinfile:
path: /opt/hadoop-3.3.6/etc/hadoop/log4j.properties
insertafter: EOF
block: |
# Define an appender for the MRAppMaster logger
log4j.logger.org.apache.hadoop.mapreduce.v2.app.MRAppMaster=INFO, mrappmaster
# Appender for MRAppMaster logger
log4j.appender.mrappmaster=org.apache.log4j.ConsoleAppender
log4j.appender.mrappmaster.layout=org.apache.log4j.PatternLayout
log4j.appender.mrappmaster.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
- name: Reloading the environment variables
ansible.builtin.shell: |
. /home/temp/.bashrc
args:
executable: /bin/bash
- name: Configuring the Hive Warehouse using hadoop
ansible.builtin.shell: |
. /home/temp/.bashrc
export HADOOP_HOME=/opt/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HIVE_HOME=/opt/apache-hive-3.1.3-bin
export PATH=$PATH:$HIVE_HOME/bin
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user
hadoop fs -mkdir /user/hive
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
schematool -dbType derby -initSchema
args:
executable: /bin/bash
- name: Creating a hive-site.xml file
copy:
dest: /opt/apache-hive-3.1.3-bin/conf/hive-site.xml
content: |
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/metastore</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hivepassword</value>
</property>
- name: Configuring Spark to use the Hive Metastore
ansible.builtin.lineinfile:
path: /opt/spark-3.3.2-bin-hadoop3/conf/spark-defaults.conf
insertafter: EOF
line: spark.sql.warehouse.dir=hdfs://localhost:9000/user/hive/warehouseThis chunk of code performs the same tasks that the first three did, but on the cluster nodes! The hosts defined here are the cluster_nodes, which include the three cluster nodes, as seen from the inventory file.